Selected Publications

Start, Follow, Read: End-to-End Full Page Handwriting Recognition
We present a deep learning model that jointly learns text detection, segmentation, and recognition using mostly images without detection or segmentation annotations. Our Start, Follow, Read (SFR) model is composed of a Region Proposal Network to find the start position of text lines, a novel line follower network that incrementally follows and preprocesses lines of (perhaps curved) text into dewarped images suitable for recognition by a CNN-LSTM network. SFR achieves state-of-the-art results on ICDAR2017 handwriting recognition competition dataset, even without using the provided region annotations.
ECCV 2018

Language Model Supervision for Handwriting Recognition Model Adaptation
We address the problem of training handwriting recognition (HWR) models for low resource languages by leveraging data from high resource languages with similar scripts through transfer learning. A langauge model in the target language is used to refine a model trained on a source language. Using this approach we demonstrate improved transferability among French, English, and Spanish languages using both historical and modern handwriting datasets.
ICFHR 2018

PageNet: Page Boundary Extraction in Historical Handwritten Documents
In this work, we present a deep learning based system, PageNet, which identifies the main page region in an image in order to segment content from both textual and non-textual border noise. In PageNet, a Fully Convolutional Network obtains a pixel-wise segmentation which is post-processed into the output quadrilateral region.
HIP 2017

Analysis of Convolutional Neural Networks for Document Image Classification
Convolutional Neural Networks (CNNs) are state- of-the-art models for document image classification tasks. However, many of these approaches rely on parameters and architectures designed for classifying natural images, which differ from document images. We question whether this is appropriate and conduct a large empirical study to find what aspects of CNNs most affect performance on document images.
ICDAR 2017
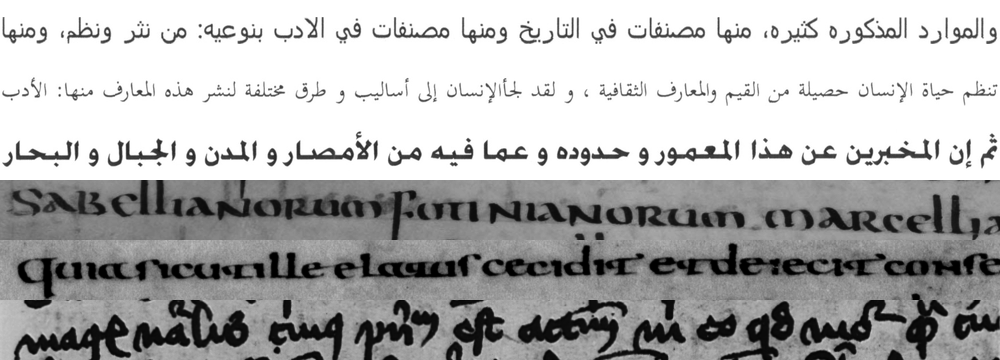
Convolutional Neural Networks for Font Classification
Classifying pages or text lines into font categories aids transcription because single font Optical Character Recognition (OCR) is generally more accurate than omni-font OCR. We present a simple framework based on Convolutional Neural Networks (CNNs), where a CNN is trained to classify small patches of text into predefined font classes.
ICDAR 2017

Document Image Binarization with Fully Convolutional Neural Networks
Binarization of degraded historical manuscript images is an important pre-processing step for many document processing tasks. We formulate binarization as a pixel classification learning task and apply a novel Fully Convolutional Network (FCN) architecture that operates at multiple image scales, including full resolution. The FCN is trained to optimize a continuous version of the Pseudo F-measure metric and an ensemble of FCNs outperform the competition winners on 4 of 7 DIBCO competitions.
ICDAR 2017
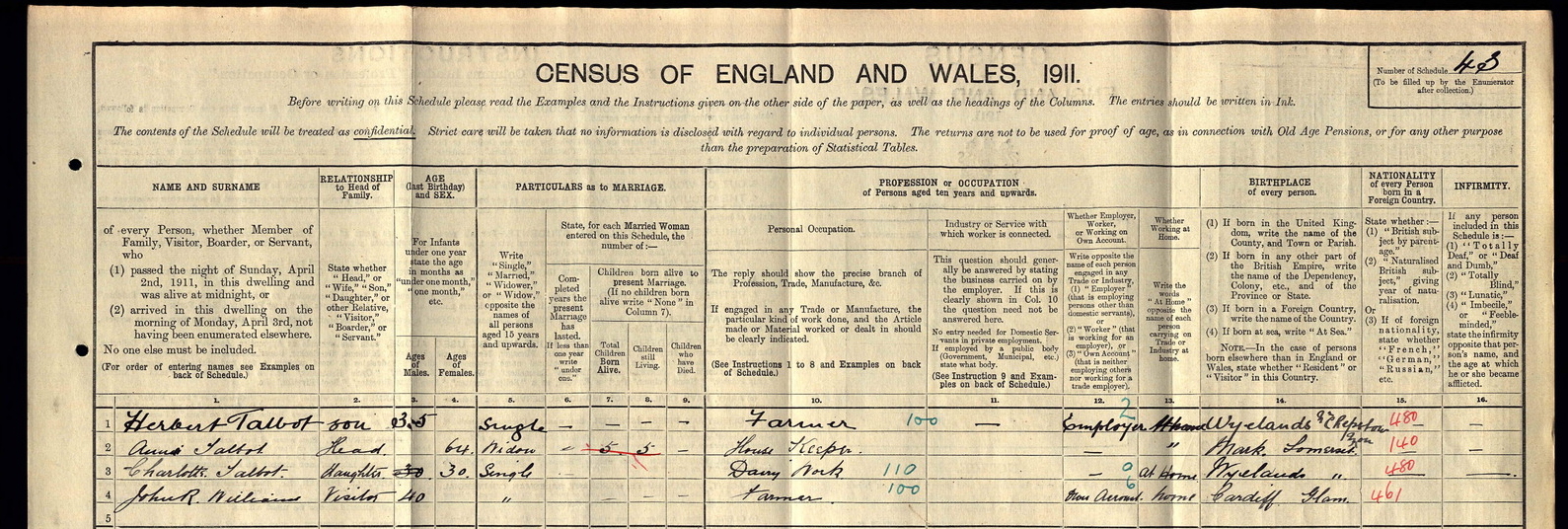
CONFIRM: Clustering of Noisy Form Images Using Robust Matching
Identifying the type of a scanned form greatly facilitates processing, including automated field segmentation and field recognition. Contrary to the majority of existing techniques, we focus on unsupervised type identification, where the set of form types are not known apriori, and on noisy collections that contain very similar document types. This work presents a novel algorithm: CONFIRM (Clustering Of Noisy Form Images using Robust Matching), which simultaneously discovers the types in a collection of forms and assigns each form to a type. CONFIRM matches type-set text and rule lines between forms to create domain specific features, which we show outperform Bag of Visual Word (BoVW) features employed by the current state-of-the-art.
MS Thesis 2016